
缓存 穿透/击穿/雪崩
http://svip.iocoder.cn/Cache/Interview/
常见的问题,可列举如下:
写入问题
缓存何时写入?并且写时如何避免并发重复写入?
缓存如何失效?
缓存和 DB 的一致性如何保证?
经典三连问
如何避免缓存穿透的问题?
如何避免缓存击穿的问题?
如果避免缓存雪崩的问题?
如果避免缓存”穿透”的问题?
🦅 缓存穿透
缓存穿透,是指查询一个一定不存在的数据,由于缓存是不命中时被动写,并且处于容错考虑,如果从 DB 查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,失去了缓存的意义。
被动写:当从缓存中查不到数据时,然后从数据库查询到该数据,写入该数据到缓存中。
在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。如下图:缓存穿透
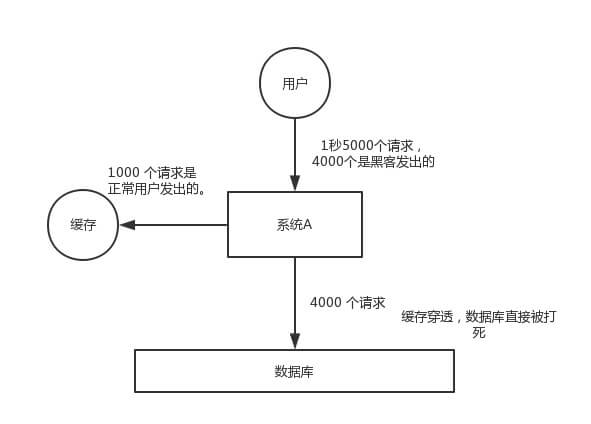
在 「为什么要用缓存?」 中,我们已经看到,MySQL 的性能是远不如 Redis 的,如果大量的请求直接打到 MySQL ,则会直接打挂 MySQL 。
当然,缓存穿透不一定是攻击,也可能是我们自己程序写的问题,疯狂读取不存在的数据,又或者“无脑”的爬虫,顺序爬取数据。
另外,一定要注意,缓存穿透,指的是查询一个不存在的数据,很容器和我们要讲到的缓存击穿搞混淆。
🦅 如何解决
有两种方案可以解决:
1)方案一,缓存空对象。
当从 DB 查询数据为空,我们仍然将这个空结果进行缓存,具体的值需要使用特殊的标识,能和真正缓存的数据区分开。另外,需要设置较短的过期时间,一般建议不要超过 5 分钟。
为什么要较短的过期时间?因为缓存久没有意义,也浪费缓存的内存。
2)方案二,BloomFilter 布隆过滤器。
这个就是在查询缓存前再加一个hashset缓存判断key是否存在
在缓存服务的基础上,构建 BloomFilter 数据结构,在 BloomFilter 中存储对应的 KEY 是否存在,如果存在,说明该 KEY 对应的值不为空。那么整个逻辑的如下:
1、根据 KEY 查询【BloomFilter 缓存】。如果不存在对应的值,直接返回;如果存在,继续向下执行。【后续的流程,就是标准的流程】
2、根据 KEY 查询在【数据缓存】的值。如果存在值,直接返回;如果不存在值,继续向下执行。
3、查询 DB 对应的值,如果存在,则更新到缓存,并返回该值。
可能有胖友不是很了解 BloomFilter 布隆过滤器,会有疑惑,为什么 BloomFilter 不存储 KEY 是不存在的情况(就是我们方案二反过来)?
BloomFilter 存在误判。简单来说,存在的不一定存在,不存在的一定不存在。这样就会导致,一个存在的 KEY 被误判成不存在。
同时,BloomFilter 不允许删除。例如说,一个 KEY 一开始是不存在的,后来数据新增了,但是 BloomFilter 不允许删除的特点,就会导致一直会被判断成不存在。
当然,使用 BloomFilter 布隆过滤器的话,需要提前将已存在的 KEY ,初始化存储到【BloomFilter 缓存】中。
🦅 选择
这两个方案,各有其优缺点。
缓存空对象
BloomFilter 布隆过滤器
适用场景
1、数据命中不高 2、保证一致性
1、数据命中不高 2、数据相对固定、实时性低
维护成本
1、代码维护简单 2、需要过多的缓存空间 3、数据不一致
1、代码维护复杂 2、缓存空间占用小
实际情况下,使用方案二比较多。因为,相比方案一来说,更加节省内容,对缓存的负荷更小。
注意,常用的缓存 Redis 默认不支持 BloomFilter 数据结构。具体怎么解决,参考如下文章:
Redis 4.0 引入 Module 机制,支持 Server 自定义拓展。而 RedisBloom ,就是 Redis BloomFilter 的拓展。
Redis-Lua-scaling-bloom-filter
Lua 脚本,实现 BloomFilter 的功能。
Java Redis 库,实现 BloomFilter 的功能。
艿艿的遐想:因为 BloomFilter 布隆过滤器存在的误判的情况,如果最后去 DB 查询不到数据的情况,是不是可以结合方案一,缓存空对象到【BloomFilter 缓存】中。后来想想,必要性不大,因为 BloomFilter 布隆过滤器误判率很低,没必要把方案复杂化,大道至简。
另外,推荐看下 《Redis架构之防雪崩设计:网站不宕机背后的兵法》 文章的 「一、缓存穿透预防及优化」 ,大神解释的更好,且提供相应的图和伪代码。
如何避免缓存”雪崩”的问题?
🦅 缓存雪崩
缓存雪崩,是指缓存由于某些原因无法提供服务( 例如,缓存挂掉了 ),所有请求全部达到 DB 中,导致 DB 负荷大增,最终挂掉的情况。
🦅 如何解决
预防和解决缓存雪崩的问题,可以从以下多个方面进行共同着手。
1)缓存高可用
通过搭建缓存的高可用,避免缓存挂掉导致无法提供服务的情况,从而降低出现缓存雪崩的情况。
假设我们使用 Redis 作为缓存,则可以使用 Redis Sentinel 或 Redis Cluster 实现高可用。
2)本地缓存
如果使用本地缓存时,即使分布式缓存挂了,也可以将 DB 查询到的结果缓存到本地,避免后续请求全部到达 DB 中。
当然,引入本地缓存也会有相应的问题,例如说:
本地缓存的实时性怎么保证?
方案一,可以引入消息队列。在数据更新时,发布数据更新的消息;而进程中有相应的消费者消费该消息,从而更新本地缓存。
方案二,设置较短的过期时间,请求时从 DB 重新拉取。
方案三,使用 「如果避免缓存”击穿”的问题?」 问题的【方案二】,手动过期。
每个进程可能会本地缓存相同的数据,导致数据浪费?
方案一,需要配置本地缓存的过期策略和缓存数量上限。
艿艿:上述的几个方案写的有点笼统,如果有不理解的地方,请在星球给艿艿留言。
如果我们使用 JVM ,则可以使用 Ehcache、Guava Cache 实现本地缓存的功能。
3)请求 DB 限流
通过限制 DB 的每秒请求数,避免把 DB 也打挂了。这样至少能有两个好处:
可能有一部分用户,还可以使用,系统还没死透。
未来缓存服务恢复后,系统立即就已经恢复,无需再处理 DB 也挂掉的情况。
当然,被限流的请求,我们最好也要有相应的处理,走【服务降级】,提供一些默认的值,或者友情提示,甚至空白的值也行。
如果我们使用 Java ,则可以使用 Guava RateLimiter、Sentinel、Hystrix 实现限流的功能。
4)提前演练
在项目上线前,演练缓存宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
另外,推荐看下 《Redis架构之防雪崩设计:网站不宕机背后的兵法》 文章的 「二、缓存雪崩问题优化」 ,大神解释的更好,且提供相应的图和伪代码。
如果避免缓存”击穿”的问题?
🦅 缓存击穿
缓存击穿,是指某个极度“热点”数据在某个时间点过期时,恰好在这个时间点对这个 KEY 有大量的并发请求过来,这些请求发现缓存过期一般都会从 DB 加载数据并回设到缓存,但是这个时候大并发的请求可能会瞬间 DB 压垮。
对于一些设置了过期时间的 KEY ,如果这些 KEY 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑这个问题。
区别:
和缓存“雪崩“”的区别在于,前者针对某一 KEY 缓存,后者则是很多 KEY 。
和缓存“穿透“”的区别在于,这个 KEY 是真实存在对应的值的。
🦅 如何解决
有两种方案可以解决:
1)方案一,使用互斥锁。
请求发现缓存不存在后,去查询 DB 前,使用分布式锁,保证有且只有一个线程去查询 DB ,并更新到缓存。流程如下:
1、获取分布式锁,直到成功或超时。如果超时,则抛出异常,返回。如果成功,继续向下执行。
2、获取缓存。如果存在值,则直接返回;如果不存在,则继续往下执行。😈 因为,获得到锁,可能已经被“那个”线程去查询过 DB ,并更新到缓存中了。
3、查询 DB ,并更新到缓存中,返回值。
2)方案二,手动过期。
缓存上从不设置过期时间,功能上将过期时间存在 KEY 对应的 VALUE 里。流程如下:
1、获取缓存。通过 VALUE 的过期时间,判断是否过期。如果未过期,则直接返回;如果已过期,继续往下执行。
2、通过一个后台的异步线程进行缓存的构建,也就是“手动”过期。通过后台的异步线程,保证有且只有一个线程去查询 DB。
3、同时,虽然 VALUE 已经过期,还是直接返回。通过这样的方式,保证服务的可用性,虽然损失了一定的时效性。
🦅 选择
这两个方案,各有其优缺点。
使用互斥锁
手动过期
优点
1、思路简单 2、保证一致性
1、性价最佳,用户无需等待
缺点
1、代码复杂度增大 2、存在死锁的风险
1、无法保证缓存一致性
具体使用哪一种方案,胖友可以根据自己的业务场景去做选择。
有一点要注意,上述的两个方案,都是建立在极度“热点”数据存在的情况,所以实际场景下,需要结合 「如果避免缓存”穿透”的问题?」 的方案,一起使用。
另外,推荐看下 《Redis 架构之防雪崩设计:网站不宕机背后的兵法》 文章的 「三、缓存热点 key 重建优化」 ,大神解释的更好,且提供相应的图和伪代码。
Last updated